When it comes to input filtering techniques for web applications and the approach taken by developers, the most common mistake we see is the use of a blocklist over an allowlist. This article aims to explain why this is a problem and why it is generally easier and more effective to implement an allowlist on an application than a blocklist. To do so Web Application Firewalls (WAFs) will be used as a case study, as entry-level WAFs serve as a good real-world example of a control that relies primarily on a blocklist approach to filtering, often leaving them vulnerable to bypass.
WAFs are a control that Application Security Consultants at MWR deal with regularly. We typically don’t recommend performing security testing of web applications while a WAF is active – as this ends up requiring more security testing effort and time to gain equivalent testing coverage of an application. However, at times, clients ask us to test in this configuration to best mimic their real-world deployment of an application. In these circumstances, bypassing WAFs can be needed to find and exploit injection vulnerabilities, such as SQL Injection (SQLi) or Cross-Site Scripting (XSS), to prove exploitability in the presence of a WAF. This article will use WAFs as a case study of ways that blocklists can often be bypassed by a sufficiently skilled and/or motivated malicious actor and, in this way, explore why an allowlist is generally more effective, in a security context, than a blocklist.
Please note that while we will be exploring multiple different techniques used to bypass WAFs, this article does not intend to claim that they are ineffective security controls. WAFs are incredibly useful defence-in-depth measures that can and should be used for web applications; however, they should not replace remedial actions that fix the root cause of vulnerabilities (for more on root causes, see this previous blog post), as they help to mitigate the chances of exploitation and do not prevent it.
What is Blocklisting?
A blocklist, also known as a blacklist, is a control on user input that determines which characters cannot be used in a specific input field. For example, an input field may exist that only accepts South African ID Numbers – which specifically consist of 13 numeric values. A blocklist can be implemented in application code on the server to disallow a user from entering a comprehensive list of explicitly-defined alphabetic or special characters. This may not seem to be a bad idea, especially if an input field needs to accept more complex input, such as comments or addresses, where potentially only a small subset of special characters is disallowed. However, when developing a blocklist, the onus is on the developers to try and consider all potentially malicious characters that may be used against their application and block them.
What is Allowlisting?
An allowlist, also known as a whitelist, contrasts the approach taken by a blocklist by specifying what characters will be accepted as part of an application’s input; any characters not part of the allowed input will, by default, be rejected. To build upon the previous example of a South African ID Number, the associated allowlist would specify that only numbers can be sent in this input field. Any input received that contains a non-numeric character will fail the allowlist check and be rejected by the application server. While, for certain fields, this may have a higher upfront difficulty than a blocklist, as a developer would need to define the input character set that is permitted for every field, it does prevent the development team from needing to identify and explicitly define all possible bad characters that should be excluded from the input.
Allowlisting vs Blocklisting
It’s useful to consider that both allowlisting and blocklisting approaches to input filtering aim to accomplish the same goal – just with two different approaches. In general, an allowlist handles user input more safely than a blocklist. The reason for this, which we have already alluded to, is that a development team would likely already know (or be able to more easily define) which is the smallest set of specific characters their input fields require. For example, ID Numbers only need numbers, names only need alphabetic characters (and, in certain locales, specific special characters such as an apostrophe), and currencies require numbers and a full stop (and potentially a currency symbol, depending on how the application is developed). Whereas, if a blocklist approach is taken, to achieve an equivalent level of protection, the development team would be required to know every possible character that is not necessary and include them in the blocklist. While this is not impossible, it does often require a significant time and effort investment by the development team to fully define this list. Even if the team spends all this time and effort to perfectly define their blocklist, it will only be as effective as a properly defined allowlist; and an allowlist is generally a lot simpler to implement.
There are always edge cases…
To contrast with these general principles, it is also instructive to observe that if special, potentially malicious, characters such as '"<>/ need to be part of the input, neither of these validation approaches would succeed in preventing all forms of malicious input from being submitted to the application. A good example of this would be the web application WolframAlpha; due to its nature as an online mathematics application, there are a large amount of weird mathematical symbols that cannot be blocked because it is needed for the website to function correctly.
However, this does not mean to say that input filtering through allowlists and blocklists are ineffective. The reason for this is because an attacker typically needs to construct specific malicious payloads to find and exploit an injection vulnerability in an application. If the attacker is significantly constrained in the payloads that they can submit, it can impede their ability to execute their payloads, slow them down so that other defence mechanisms or remediations can come into place (such as rate filtering), or even produce alerts that expose the attacker’s current attack vector.
What is a WAF?
A Web Application Firewall (WAF) is a security layer that is positioned between a web application server and a client (A client typically being a user’s browser). A WAF serves the purpose of being an application’s first line of defence and tries to prevent any malicious input from reaching the application. This is achieved by either filtering out the identified malicious part of a request (less secure) or just simply blocking the entire request (more secure). It is generally most useful in preventing payloads for injection attacks such as SQLi and XSS. An illustration of how a WAF may be implemented for a typical web application is shown in Image 1.
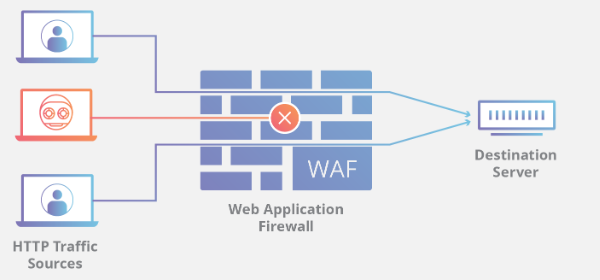
Image 1: WAF architecture that inspects users request to the server and blocks malicious payloads while allowing through non-malicious payloads. (Image from Cloudflare’s WAF learning resources.)
Entry-level WAFs operate through a set of rules called policies. These policies use a blocklist approach to try and detect malicious input and then reject it. Due to the WAF being positioned between the client and a server, and often not being developed or deployed with input by the developers of an application, it cannot make use of an allowlist approach for input validation. The security offered by these WAFs are therefore only as good as the blocklist policies being maintained on them. These policies should therefore be regularly updated to ensure that the WAF is providing maximum value. The value of these types of WAFs come in part from the speed and ease with which policy modification can be implemented, allowing for faster response to varying attack vectors. For example, during a DDoS attack, rate limiting can be quickly implemented by modifying WAF policies.
More modern and advanced WAFs incorporate machine learning and behavioural prevention techniques into their defence set to further improve their security; however, the focus of this article is on allowlists and blocklists, not WAFs, so these newer techniques will not be discussed in this article.
In the following sections, we will investigate how we can bypass an entry-level WAF and its associated blocklist to perform common injection attacks against a web server or its users. This will not be an exhaustive list of WAF bypasses; the idea behind these points is to illustrate that by obscuring data in targeted ways, it is generally possible to bypass a blocklist. There are two specific attack types that we will investigate, SQL Injection (SQLi) and Cross-Site Scripting(XSS):
- SQL Injection: SQLi is a well-known server-side vulnerability that has existed for decades; it is caused by the concatenation of untrusted input into a SQL query that allows a malicious actor to modify the query syntax to execute their own SQL commands. The most common exploitation payload used against a SQLi vulnerability (
'or 1=1 --) makes a conditional statement always return true, which passes checks that would otherwise fail, or extracts more information from the statement than originally intended. - Cross-Site Scripting: XSS is a similarly well-known client-side vulnerability that has existed for decades; it is caused by the concatenation of unencoded input into an HTML page. Whereas SQLi will target the server-side, this vulnerability is used to target the application’s users, as a browser is required for this attack to be performed. This vulnerability allows for the execution of arbitrary HTML, CSS, and/or JavaScript on users’ browsers.
Bypassing entry-level WAFs
The blocklist approach used by many entry-level WAFs, which relies on taking a known bad value and blocking it, can often be bypassed by simply altering the known bad value into something that performs the same action but is not on the blocklist explicitly.
Think of it as the difference between baked potatoes and chips. Both are made from the “known-bad” ingredient of potatoes, but someone may refuse the baked potatoes, but not the chips. This would be the same for our payloads, the known-bad payloads are blocked, while the changed (obfuscated) payloads are allowed through. Several simple techniques for obfuscating potentially malicious web application payloads is presented in this section.
Bypassing a WAF to perform SQLi using multi-line comments
Potentially the simplest and most effective bypass for SQLi payloads against a WAF is by using multi-line comment characters. We can insert multi-line comments into the payload that obfuscate the payload’s format, but that won’t be processed as part of the query by the SQL engine, while the original payload would be processed. This technique works, since SQL, similarly to other coding languages, has comment characters that are used to allow developers to insert text to help people understand their code; in general, comment characters are stripped out during the compilation of a program, so it is not considered code. An example of a comment in SQL is /*TEXT HERE*/, where anything between the asterisks is not compiled; and this can span multiple lines in a SQL query.
The most common SQL Injection payload (shown below) is of course by default blocked by most, if not all, WAFs.
' or 1=1 --
However, we can obscure the format of this payload by inserting /*MWR*/ between some of the key words. I’ve found in testing that you generally need to obscure the "OR" and "1=1" parts of the payload for this to be successful, such as:
' O/*MWR*/R/*MWR*/ 1/*MWR*/=1 -/*MWR*/-
This payload will then not be blocked by a WAF and can be used (and modified) to target the server and successfully test for SQLi and retrieve data from the application.
Case Toggling Bypasses
Case Toggling is a technique where the case of each lEtTEr iN a WoRD or payload is changed to try and obfuscate the payload being sent. This may seem like a simple technique to a human, as we can clearly read the intended payloads, even with the case toggling. However, it must be remembered that computers treat each upper- and lower-case letter as separate unique values. Which means that to a computer "This" and "this" are not the same string at the binary level. Consider the SQLi and XSS payloads below:
SQLi - ' union select 1,2,3 #-- XSS - alert(document.cookie)
These payloads will be blocked by every WAF as they are very common payloads; the SQLi payload is a common payload used in the process of exploiting a database and the XSS payload will cause a pop up to show on the screen with any cookies that you currently have on the website (provided the HttpOnly flag on the cookies is set to False). We can use the case toggling technique to obscure these payloads into a format that could bypass the WAFs:
SQLi - ' uNIoN SeLEct 1,2,3 #-- XSS - aLeRT(DoCUmenT.CoOkIe)
This approach is generally quite useful if the blocklist that has been implemented is trying to match case-sensitive keywords, phrases or patterns. With computer logic, simple checks for equality between words will only match if their cases match. In order for case-insensitive checks to work, words may need to be forced into the same case or a blocklist that contains every possible case-permutation of a payload or pattern would need to be generated. However, this is a case where an allowlist may not resolve the issue either, as if all the necessary characters are allowlisted that allow case toggling, then the payloads would also be allowed through. This is why it is important to remember that while input filtering is an extremely useful mitigation, it is not a remedial action. It does not fix the vulnerability; it simply makes it harder to exploit.
Data Encoding Bypasses
Double URL Encoding
The next technique we will use to bypass a WAF’s blocklist is double URL encoding of the payload. Consider the following SQLi and XSS payloads that we have already seen:
SQLi - ' union select 1,2,3 #-- XSS - alert(document.cookie)
URL encoding, also called percent encoding, uses a % for all special characters, or all characters. Every ASCII character maps to a specific value in the encoding schema, even a % which becomes %25. URL encoding is commonly required when transmitting data to web applications, as characters that have special meaning in the HTTP protocol, or in a URL, must be encoded if they need to be transmitted as part of a HTTP message.
Sometimes, due to an application’s architecture, a backend server may be able to handle user-supplied input that was URL encoded multiple times by the client-side. This would typically happen in applications’ that may do some initial processing on a front-end server, which would URL decode the data a single time while processing it. This front-end server would then forward the decoded data to a backend server that decodes it again, revealing the original data. The possibility for this may be overlooked, because if decoding is attempted on a block of text that does not contain any URL-encoded data, nothing changes and the data processing proceeds as expected. This can become easy to miss, especially as applications grow larger (and more architecturally complex) and multiple teams handle user data.
If a WAF is looking for a ', it will likely also check for its encoded value, %27 as well, as URL encoded data is automatically decoded by web servers as required by web standards (such as Section 2.4 of RFC 3986). However, as double URL encoding is not commonly encountered with web applications, it is unlikely that it would check for the double encoded value, %2527. This can be applied to the below payloads as well to bypass a WAF only checking for unencoded payloads (note that in our examples, we have encoded all characters, and not simply special characters).
SQLi (single encoded) - %27%20%75%6e%69%6f%6e%20%73%65%6c%65%63%74%20%31%2c%32%2c%33%20%23 %2d%2d SQLi (double encoded) - %2527%2520%2575%256e%2569%256f%256e%2520%2573%2565%256c%2565%2563 %2574%2520%2531%252c%2532%252c%2533%2520%2523%252d%252d XSS (single encoded) - %3c%73%63%72%69%70%74%3e%61%6c%65%72%74%28%64%6f%63%75%6d%65%6e%74 %2e%63%6f%6f%6b%69%65%29%3c%2f%73%63%72%69%70%74%3e XSS (double encoded) - %253c%2573%2563%2572%2569%2570%2574%253e%2561%256c%2565%2572%2574 %2528%2564%256f%2563%2575%256d%2565%256e%2574%252e%2563%256f%256f%256b%2569%2565%2529 %253c%252f%2573%2563%2572%2569%2570%2574%253e
Encoded Data Parameters
It is worth noting that other types of standardised encoding formats are used on the internet, such as base64 encoding, HTML encoding, Unicode encoding etc. An application could, for example, decide to base64 encode a parameter in JavaScript that is later sent to the server. The application receiving this data would function correctly, as it would know to decode the data before using it. This, however, can be leveraged an attacker to smuggle a payload past a WAF by correctly encoding their malicious payload before including it in the HTTP message being sent to the application.
The only means by which a WAF would correctly scan user input for malicious payloads, in the context of arbitrary user input encoding, is if the WAF is configured to decode the input before scanning it in the exact same way as the application itself, which may require input from the application developers in the development of the WAF policies.
Conclusion
The goal of this article was to show the reader that when it comes to input validation there are two approaches: allowlists and blocklists. While both of these approaches achieve the same goal if implemented perfectly, the effort and room for error with a blocklist is much higher than with an allowlist. To showcase this, we discussed some WAF bypass techniques that alter the format of data so that it won’t get blocked by a blocklist implemented by a control like a WAF or application input filtering.
It is important to remember that input filtering is a strong security control but does not fix a vulnerability, rather, it further improves the security posture of an application. If an application needs to allow dangerous characters or payloads, neither an allowlist or a blocklist will be able to prevent that while maintaining functionality. However, with a blocklist, the room for error is much larger and the burden of knowledge is on the developers (as they need to know all potentially malicious characters). But, with an allowlist the developer only needs to allow the characters necessary for the functionality of the application, making it simpler to implement and having less room for error due to unknown attacker techniques or unknown malicious characters.
Although a fair portion of this article spoke about bypassing WAFs, they are a great security tool when used as a defence-in-depth control. But it should be noted that WAFs should only serve the function of defence-in-depth and are not a remedial action to vulnerabilities themselves; when trying to prevent vulnerabilities holistically, the root cause of each type of attack should be addressed and a WAF should be implemented in conjunction with these root cause fixes (Remedial Actions) to further increase the security of the application.
To maximise the security posture of an application, we would personally recommend implementing an allowlist on input fields once the appropriate remedial actions have been undertaken, then furthering your application’s security by using a WAF. This serves to layer the security controls implemented on your application, so that even if one of the layers fails, the other layers may prevent a compromise of the application.