Introduction
Authentication has come a long way in recent years. As the primary barrier to entry for almost all applications, advancements had to be made to ensure that accounts, and the sensitive data stored within them, remain secure. In this blog post, we will talk about Type 3 authentication, biometric authentication, and the fundamental misunderstanding that leads to its incorrect use.
Types of Authentication
As we discussed in a previous series of blogposts, there are three main types of authentication:
- Type 1 – Something you know, such as a password or passphrase
- Type 2 – Something you have, such as your phone to receive an OTP code
- Type 3 – Something you are, such as your fingerprint, facial, or voice-pattern
The most common type of authentication is Type 1. This is used almost everywhere in the modern world, requiring you to provide your username and password to authenticate. This provides concrete proof that you are who you say you are. The username and password combination has to match 100% in order for you to be authenticated. Of course, someone could guess your password, but, if the authentication mechanism is working properly, they would have to guess it 100% correctly to authenticate. Not even 99.99% would do, it has to match 100%.
To also further protect against password guessing and impersonation, we have observed that multi-factor authentication (MFA) is important. Rather than just relying on a single type of authentication, by combining multiple types, we can make it incredibly hard for a threat actor to gain unauthorised access. Then, it isn’t even enough that they guess your password, they also have to have access to your phone to accept the 2FA prompt or to receive the One-Time Pin (OTP). While attacks such as 2FA fatigue (https://www.beyondtrust.com/resources/glossary/mfa-fatigue-attack) or Sim Swapping (https://www.microsoft.com/en-us/microsoft-365-life-hacks/privacy-and-safety/what-is-sim-swapping) can still be used, this will have raised the bar quite significantly.
This does, however, then raise the question: With all of this historic advancement, why are we suddenly going backwards when it comes to authentication security?
This is the question that we were faced with after several assessments of authentication mechanisms boasting about the use of Artificial Intelligence (AI) or Machine Learning that incorporated Type 3 authentication.
Revealing the AI Problem
There is a devil in the details of Type 3 authentication that isn’t commonly spoken about: the fact that Type 3 authentication brings a new dimension into the world of authentication, called the certainty factor.
With Type 1 and Type 2, the decision boundary is Boolean; it is either true, or false. You either know the password or you don’t. You either accept the 2FA prompt or you don’t. It isn’t quantum physics, where the state of authentication can be anything other than true, or false. However, this is not the case for Type 3 authentication.
It is not often discussed, but biometric authentication doesn’t actually have a static true or false value. Sure, the final answer is abstracted to that, but behind the scenes, the certainty factor plays a massive role. To dive into this, we must get a bit technical. Let’s start by explaining what actually happens behind the scenes of Type 3 authentication.
Understanding Biometric Authentication
When Type 3 authentication is used, a series of steps is performed, as shown in Diagram 1.
 Diagram 1: Steps performed when Type 3 Authentication is performed
Diagram 1: Steps performed when Type 3 Authentication is performed
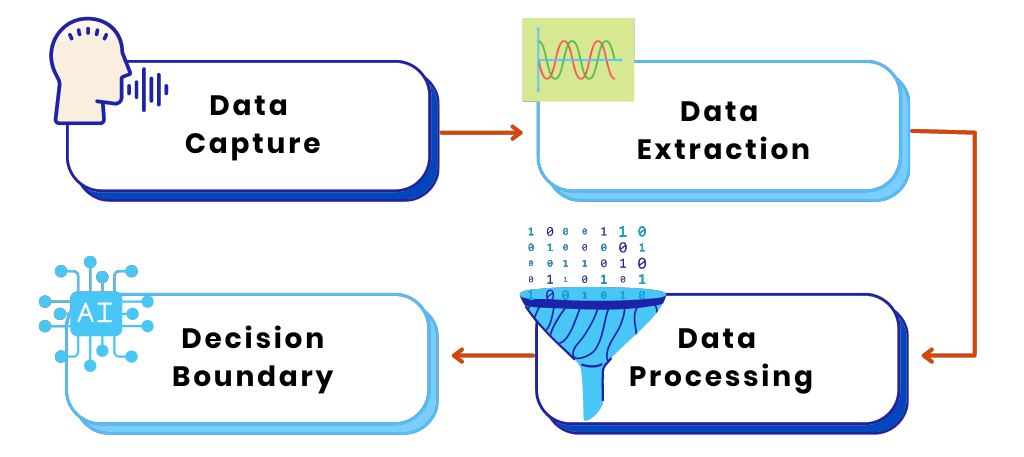 Diagram 1: Steps performed when Type 3 Authentication is performed
Diagram 1: Steps performed when Type 3 Authentication is performedThe first step is data capture. For something such as fingerprint authentication, it involves capturing the ridges on your finger. For voice authentication, it involves capturing a sample as you speak. This is where the first problem creeps in. Data capture and the process of doing so can introduce errors, background noise as you speak, or residue on the scanner obscuring your fingerprint.
The second step is data extraction. Not all of the data from the first step is relevant. For example, we need to extract only your voice from the sample or extract only your fingerprint ridges. Again, errors can be introduced at this step as logic is applied in an attempt to extract only the necesssary information from the raw data.
The third step is data processing. In this step, we need to process the information into a format that can be compared against what we have on record. This step is also known as the feature extraction step. In essence, we are trying to extract features that can uniquely identify you. As an example, your voice sample can be converted to Mel Frequency Cepstral Coefficients (MFCC), that can uniquely identify your voice. The issue with this step is data loss. We are taking a large amount of data and boiling it down to its absolute essence. Any error in the initial pipeline will thus be amplified at this step.
In the fourth step, we finally come to the decision boundary. The big taboo of Type 3 authentication. In machine learning, or AI, as it is better known, nothing is ever known with 100% certainty. Every time we build a feature set of your voice, iris, or fingerprint, it would not 100% match the next attempt. Thus, when we compare one set to another, instead of getting a true or false answer, we get a certainty score. For example, we can say that based on the distance comparison between two feature sets, we have 80% confidence that the two feature sets are from the same user. As the creators of the system, we have to set the decision boundary. Is an 80% match sufficient for us to abstract this entire pipeline into a true decision? Or do we have to be 85% sure before we make that call? Let’s dive even deeper into this authentication rabbit hole.
False, what now?
In order to prove the effectiveness of our biometric authentication solution and compare it to others out there, we have to calculate three different values, namely the False Acceptance Rate (FAR), False Rejection Rate (FRR), and the Crossover Error Rate (CER). Let’s explain these terms in a bit more detail in Diagram 2:
Diagram 2: The three different values of biometric authentication
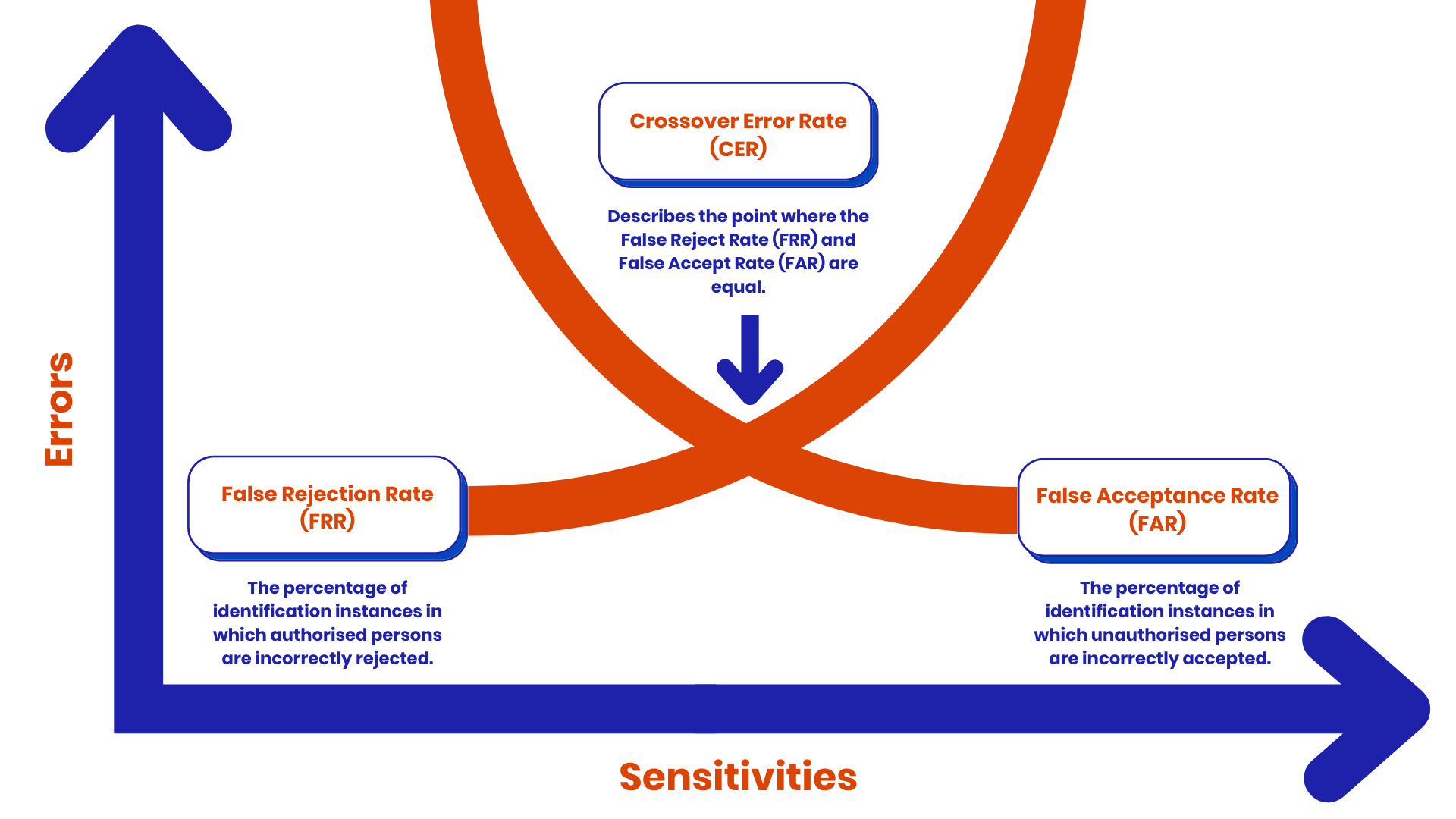 Diagram 2: The three different values of biometric authentication
Diagram 2: The three different values of biometric authenticationWhen we set a decision boundary, some legitimate users may be blocked from accessing the system. Basically, even though they are truly who they say they are, our system can reject their authentication attempt if it is not sufficiently confident in its decision. If, for a particular authentication attempt, a confidence score of 79% is determined, but the decision boundary was set to 80%, our system would return false. Comparing the number of times this happened against the total number of authentication attempts, we would get an FRR.
On the other hand, if the decision boundary were to be set too low, it may allow an imposter to authenticate as a legitimate user. Maybe our decision boundary for the voice authentication system was set to 50% confidence, and an imposter tries to sound like one of our legitimate users, they may very well score a 51%. Of course, we wouldn’t see this, we would only see the final decision of true, allowing the imposter access. Taking the total number of times this happens across the total number of authentication attempts provides an FAR.
In an ideal world, we want both values to be 0%. But that’s simply not possible in practice. These values are fighting against each other. If we want to have a low FAR, we need to set the decision boundary high, which, in turn, will cause the system to block legitimate users, raising the FRR. If we want to have a smooth process for legitimate users, we need to lower the decision boundary, allowing more imposters, thus raising the FAR. To tangibly understand and compare the accuracy of our system, we use the CER. CER is the point where we set the decision boundary in such a way that the FAR and FRR values are the same.
CER is incredibly important. I can boast that my system has an FAR of 1% and an FRR of only 5%. My competitor can say that with only an FAR of 0.1% they have an FRR of 10%. Which of these two systems is better? The proof is in the CER. We must determine the CER for both systems to be able to truly determine their accuracy.
The True Issue of Type 3
Now we can finally tie it all together. The real problem with Type 3 authentication is that we always have a CER of larger than 0%. Something that simply does not exist with Type 1 and Type 2. Sure, Type 1 and Type 2 can be compromised, but both don’t suffer from the fact that the actual authentication pipeline itself can cause an error in the decision being made. This vulnerability is specifically reserved for Type 3. If we just look at voice recognition alone (https://ieeexplore.ieee.org/abstract/document/9442674), we can see that even in modern times we are currently dealing with CER values of around 5%. To put this in perspective, if the CER was used as the decision boundary, 5 out of every 100 authentication attempts would allow an imposter to gain access.
Does this mean that Type 3 should not be used? Absolutely not! Type 3 has its place. But the key piece of information that is often missed today is that Type 3 is almost always used as a secondary factor of authentication. But wait you say, don’t I only use my fingerprint to unlock my phone? Of course you do, but you are missing that there is already an embedded Type 2 authentication, the fact that you have to have your phone on you (as well as the fact that most modern phone OSes will periodically require the user to enter their password to gain access).
The issue is not with Type 3 in these cases where 2FA is also applied, the issue is with sensitive cases, such as using voice recognition to verify who you are on a call. In isolation, Type 3 authentication does not hold up to scrutiny. In order for it to be secure, it has to be combined with an additional factor. Otherwise, we are back to square one by having weak authentication systems like we had in the past that only relied on a password.
Where does this leave us?
Biometric authentication cannot in its current form fully replace both Type 1 and Type 2 authentication. Especially given the recent advancements in the field of machine learning where your voice can be emulated by providing an AI model with a couple seconds of samples of your voice. We have been down this road. We have seen the flaws of single factor authentication and how easily it can be bypassed given the right set of circumstances. Let’s be mindful of where Type 3 is best suited and be aware of its limitations. Let’s use Type 3 as it should be used, the same as we use the other two types, to complement each other and to create a single secure authentication system.